

Datenqualität klingt zunächst nach einem harmlosen Begriff. Bei der ersten Begegnung besteht die Assoziation in der Regel mit großen, teils fehlerhaften, Tabellen, Mathematik und komplexen Statistiken. Die Folgen können jedoch sehr real sein. In meinem früheren Artikel „Data Cleaning: Fallstricke und Lösungen“ habe ich bereits einen näheren Blick auf einige der Formen geworfen, in denen Datenqualitätsprobleme auftreten können. Darin ging es auch um verschiedene Ansätze zur Verbesserung der Datenqualität, sowie Einblicke in die Auswirkungen einer unzureichenden Datenqualität auf das Geschäft. Heute möchte ich mich dem Thema aus einer konkreteren Perspektive nähern.
Konkret werde ich im Folgenden zwei Datenqualitätsprobleme unterschiedlicher Ausmaße untersuchen und versuchen, aus daraus Erkenntnisse zu ziehen. Schließlich werden wir die gewonnenen Erkenntnisse untersuchen und einen allgemeinen Ansatz zur Abwägung von Datenqualitätsrisiken und -strategien entwickeln.
Erster Fall: Challenger-Explosion, 1986
Im Januar 1986 startete die NASA die Raumfähre Challenger, mit sieben Astronauten besetzt, zu ihrer zehnten Mission. Nur wenige Augenblicke nach dem Start explodierte die Raumfähre, was den Tod der gesamten Besatzung zur Folge hatte. Es herrscht weitgehend Einigkeit darüber, dass die Ursache der Explosion ein Dichtungsring war, der unter extrem niedrigen Temperaturen und hohem Druck beim Start versagte. Infolgedessen entwichen brennbare Gase aus ihren Behältern und entzündeten sich, was schlussendlich zur Katastrophe führte. Wenn man über den technischen Aspekt hinausblickt, stellt man fest, dass das Dichtungsring-Problem schon lange im Voraus bekannt war und mit einer besseren Datenhaltung und besseren Entscheidungsverfahren hätte verhindert werden können. Tatsächlich wurden Bedenken bezüglich der Dichtung bereits neun Monate zuvor geäußert, und sogar der Hersteller erhob Einwände gegen dessen Nutzung. Unglücklicherweise operierte das Management der NASA auf Basis von inkonsistenten und unvollständigen Daten.
Die fragliche Komponente wurde in mehreren Datenbanksystemen dokumentiert, von denen jedes einen anderen Aspekt der Herstellung und Planung betraf. In einigen dieser Systeme wurde der Dichtungsring korrekterweise als „kritisch“ deklariert, während er in anderen als „redundant“ eingestuft wurde, d.h. sein Ausfall würde durch andere Bauteile abgesichert werden. Die Redundanz mehrerer Systeme bedeutete auch, dass die Informationen oft nicht identisch gehalten wurden und daher voneinander abwichen. Dies führte dazu, dass ein Ingenieur die O-Ring-Untersuchung auf der Grundlage der Informationen aus nur einer Datenbank als gelöst abschloss und damit alle weiteren technischen Untersuchungen beendete.
Die Existenz mehrerer Systeme führte außerdem dazu, dass unvollständige Informationen verwendet wurden. Obwohl die notwendigen Daten zur Analyse des Temperatureinflusses auf die Dichtung zur Verfügung standen, waren sie auf die verschiedenen Datenbanken verteilt, weshalb letztlich nur ein Teil davon sowohl von der NASA als auch vom Hersteller für die Regressionsanalysen verwendet wurde.
Natürlich kann die Challenger-Katastrophe nicht allein auf Fragen der Datenqualität zurückgeführt werden. In vielen Fällen kam es zu Kommunikationsversagen, und auch die Office-Prozesse der NASA truge zur unzureichenden Verteilung von Informationen bei.
Lessons Learned
Diese Geschichte zeigt mehrere Fehler bei der Speicherung und Anwendung von Informationen auf. Erstens führt die Aufrechterhaltung redundanter Systeme ohne ordnungsgemäße Synchronisationsverfahren zu inkonsistentem Wissen und damit zu inkonsistenten Entscheidungen. Eine normalisierte und gut gepflegte Datenbank hätte eine Vereinfachung und Verbesserung der betrieblichen Abläufe ermöglicht. Zweitens verließen sich sowohl Ingenieure als auch das Management unwissentlich auf unvollständige Informationen. Dies ist zwar sowohl ein Verfahrens- und ein Datenqualitätsproblem, aber es zeigt auch, dass die Datenzugänglichkeit ein wesentlicher Bestandteil der Datenstrategie ist.
Zu guter Letzt zeigt diese Geschichte, dass selbst große Sorgfalt bei technischen Details und ein großer Planungsaufwand durch das Fehlen einer effektiven Datenstrategie zunichte gemacht werden können.
Fall zwei: Aber Google Maps sagte…
Im Jahr 2016 erhielt eine in Texas geborene Frau einen Anruf von ihren Nachbarn, dass ihr Haus von einer Abrissfirma zerstört worden sei. Bei der Untersuchung stellte sich heraus, dass das Unternehmen seinen Auftrag nach bestem Wissen und Gewissen am korrekten Ort ausgeführt hatte. In Wirklichkeit war die richtige Adresse ein anderes Haus einen Block weiter.
Dieser Fehler war offensichtlich auf ein Datenproblem in Form einer falschen Adressangabe zurückzuführen. Die fehlerhaften Daten waren jedoch nicht ihre Eigenen. Die Abbruchmannschaft hatte die angegebene Adresse in Google Maps eingegeben und einen falschen Standort erhalten.
Wie das Bild unten zeigt, listet Google bis heute den gleichen Standort für beide Adresse.
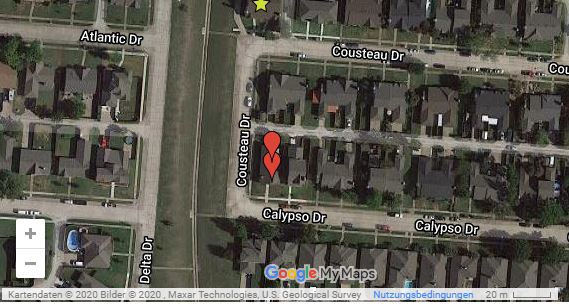
Lessons Learned
Über Fälle wie diesen wird weltweit regelmäßig berichtet. Manchmal handelt es sich um einen irrtümlichen Abriss, manchmal um Fahrer, die blind ihrem GPS folgen und ihre Fahrzeuge in Flüsse, Seen oder Häuser manövrieren. Diese unterhaltsamen Anekdoten zeigen eine grundlegende Diskrepanz bei der Datenqualität auf. Für ein Unternehmen wie Google haben Ungenauigkeiten ihrer Karten sehr geringe Konsequenzen, weshalb der Aufwand einer umfassenden Korrektur nicht unternommen wird.
Probleme entstehen, wenn man sich auf diese Daten in einem Kontext verlässt, in dem mehr auf dem Spiel steht, sei es der Abriss eines Hauses oder die Übergabe des eigenen Lebens in die Hände eines GPS-Systems. Was die daraus gezogenen Lektionen betrifft: Bedenken Sie bei der Auswahl einer Datenquelle die Auswirkungen fehlerhafter Informationen, und wenn keine zufriedenstellende Datenquelle zur Verfügung steht, sollten Sie sich erst vergewissern, bevor Sie Maßnahmen ergreifen.
In diesem Fall hätte es genügt, das Straßenschild zu überprüfen.
Anmerkung: Wenn man sich auf Daten von Dritten stützt, ist es notwendig, zu bewerten, ob der Datenlieferant ein eben so hohes Interesse an deren Richtigkeit hat wie der Benutzer.
Schlussfolgerung: Abwägung der Auswirkungen und entsprechende Priorisierung
Wir haben uns nun zwei Fälle angesehen, in denen unzureichende Datenqualität zu schwerwiegenden Folgen führte oder dazu beitrug. Sie sind zwar im Ergebnis ähnlich, unterscheiden sich aber darin, dass die NASA ihre eigenen Daten sammelte und pflegte, während sich das Abrissunternehmen auf externe Daten stützte.
In den meisten Fällen datengestützter Entscheidungsfindung steht natürlich nicht annähernd so viel auf dem Spiel, aber das Konzept hat Bestand. Unternehmen sind oft überfordert, wenn es darum geht, die Qualität der Daten zu beurteilen, die sie möglicherweise über Jahrzehnte hinweg gesammelt haben.
Der oft gewählte Ansatz, die Frage „Welche Daten sind am wichtigsten?“ zu stellen, ist meiner Meinung nach fehlerhaft. Sie sollte vielmehr mit der Formulierung „Wo können fehlerhafte Daten den größten Schaden anrichten? Wenn der potentielle Schaden wider Erwarten kein Faktor ist, sollte die Priorisierung nach dem potentiellen Nutzen erfolgen, sei es wirtschaftlich oder anderweitig.