In vielen Unternehmen schlummern sie bereits in verschiedensten Systemen, Berichten oder Excel-Listen: Nachhaltigkeitsdaten. Doch sobald es darum geht, diese Daten strategisch zu nutzen, stellt sich schnell eine zentrale Frage: Was genau sollen wir eigentlich analysieren? Welche Kennzahlen sind wirklich relevant – und wie finde ich sie?
Nachhaltigkeits-Analytics entfalten ihren Mehrwert nicht durch Datenmengen, sondern durch Fokussierung. In diesem Beitrag zeigen wir, wie Unternehmen die richtigen Kennzahlen auswählen und ihre Nachhaltigkeitsdaten gezielt für Analysen und Entscheidungen nutzbar machen. Dafür stellen wir Tools und Strategien vor, die sich bei uns in der Beratung bewährt haben.
Warum die Wahl der richtigen KPIs entscheidend ist
Wer alles messen will, misst am Ende nichts richtig. Gerade im Kontext von Nachhaltigkeit ist die Versuchung groß, möglichst viele Kennzahlen zu erfassen: CO₂, Wasserverbrauch, Biodiversität, Gender-Diversity, Schulungsstunden, Lieferantenbewertungen, Social Impact … Die Liste ist lang – und wächst mit jeder neuen Regulierung.
Doch echte Steuerungswirkung entsteht nicht durch möglichst viele KPIs, sondern durch strategisch relevante Anwendungsfälle (auch Use Cases genannt). Viele Unternehmen orientieren sich an externen Standards und Frameworks – was grundsätzlich hilfreich ist. Aber: Der wirkliche Mehrwert entsteht nicht durch das bloße Befolgen von Checklisten, sondern durch eine bewusste Auseinandersetzung mit der eigenen Organisation.
Dabei helfen Fragen wie:
- Welche Nachhaltigkeitsthemen sind in unserem Unternehmen wesentlich? (PS: Wie die Wesentlichkeitsanalyse hier einzahlt, werden wir uns in einem der nächsten Blogs noch genauer angucken)
- Welche Nachhaltigkeitsziele verfolgt unser Unternehmen?
- Welche Entscheidungen wollen wir datenbasiert treffen?
- Welche Kennzahlen helfen uns dabei, Fortschritte sichtbar und steuerbar zu machen?
Wie entwickeln wir impactvolle Anwendungsfälle im Unternehmen?
Gute Analysen beginnen mit den richtigen Fragen – nicht mit Dashboards.
Ein bewährter Weg: Gespräche mit verschiedenen Fachbereichen. Denn oft liegen die besten Ideen dort, wo Herausforderungen im Alltag spürbar sind. Um diesen Prozess zu strukturieren, nutzen wir Methoden aus der Datentreiber-Toolbox, insbesondere:
Durch den Business Models Canvas können Use Cases identifiziert werden. Hierzu kann man verschiedene Perspektiven nutzen:
- Welches Problem löst der Anwendungsfall?
- Welche Lösung kann durch den anwendungsfall verbessert werden?
- Welchen Benefit wünschen wir uns durch einen bestimmten Anwendungsfall?
Ein weiterer Canvas wird genutzt zur Analyse der Wertschöpfungskette. Auch hier kann eine Analyse helfen Anwendungsfälle zu identifizieren, um Themen in der Wertschöpfungskette zu adressieren.
Der Prozess der Identifikation von Anwendungsfällen ist nicht nach einem Workshop vollendet, sondern sollte regelmäßig wiederholt werden, um Anwendungsfälle zu hinterfragen zu verbessern und neue zu finden. Genauso wie sich ein Unternehmen weiterentwickelt und verändert, verändern sich seine Anwendungsfälle mit.
Die „User Value Story“ – Klarheit in einem Satz
Identifizierte Anwendungsfälle sollten gut definiert sein. Hierzu nutzen wir gerne die User Value Story (siehe Bild). In diesen 5 Schritten erklärt man in einem Satz wer mit welchen Daten, welche Erkenntnisse erlangt und hierdurch sein Handeln verbessern und Mehrwerte schaffen kann.

Anwendungsfälle identifiziert – was nun?
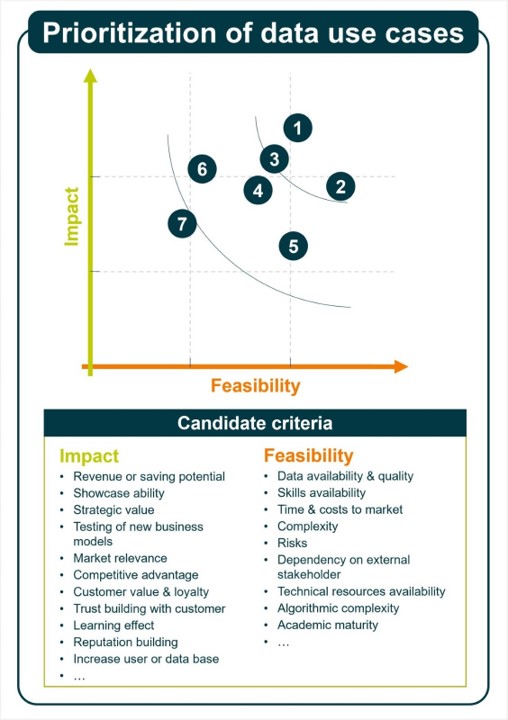
Insbesondere nach der ersten Analyse nach dem obigen Format werden einige Anwendungsfälle zusammenkommen, die alle strategisch sinnvoll sind. Hier ist es wichtig weiter zu priorisieren: nicht alles ist gleich wertvoll und nicht alles ist gleich gut umzusetzen. Hier hilft die Prioritätsmatrix, in welcher die Anwendungsfälle nach Machbarkeit und Business Impact priorisiert werden können. Hierzu macht es Sinn Business Impact und Machbarkeit tiefergehend zu definieren und ggf. Skalen für die Bewertung entworfen werden. Das erleichtert den Bewertungsprozess der Anwendungsfälle.
Aus Daten werden Erkenntnisse
Hoch priorisierte Use Cases verdienen eine vertiefte Betrachtung. Es sollte analysiert werden welche Erkenntnisse man sich vom Anwendungsfall erhofft und was für Informationen man dafür benötigt. Dabei ist wichtig: Einzelkennzahlen sind selten aussagekräftig. Erst im richtigen Kontext liefern sie echten Mehrwert:
- Im Zeitverlauf: Entwickeln wir uns in die richtige Richtung?
- Im Vergleich zu Zielen: Sind wir auf Kurs?
- Im Branchenvergleich: Wo stehen wir im Markt?
- Im Kontext der Wertschöpfungskette: Wo entstehen die größten Effekte?
Auch zur Entwicklung wirkungsvoller Lösungen, wie Dashboards, gibt es einen Analytik & KI-Anwendungsfall Canvas von Datentreiber. In diesem spielen die oben genannten Aspekte eine maßgebliche Rolle, um den strategisch wichtigen Anwendungsfall in sinnvolle KPIs und Daten runterzubrechen, um aus Zahlen echte Steuerungsimpulse zu machen.
Fazit: Relevanz schlägt Vollständigkeit
Wer den Überblick über seine Nachhaltigkeitsdaten behalten will, braucht Klarheit darüber, was analysiert werden soll – und warum. Nur dann werden aus Daten echte Erkenntnisse. Und nur dann gelingt es, Nachhaltigkeit nicht nur zu dokumentieren, sondern aktiv zu steuern.
Der Schlüssel liegt nicht in der Fülle an Daten, sondern in der Fokussierung auf das Wesentliche: strategisch relevante Kennzahlen, die Entscheidungsprozesse unterstützen und echten Impact sichtbar machen.
Wir unterstützen dich gerne bei der Identifikation und Umsetzung wertvoller Nachhaltigkeits-Anwendungsfälle!
Du möchtest datengetriebene Nachhaltigkeit in Ihrem Unternehmen gezielt voranbringen? Dann empfehlen wir unseren:
Sustainability Use Case Ideation Workshop
In diesem Format:
- führen wir gezielte Interviews mit Fachexpert*innen,
- identifizieren gemeinsam Ihre wertvollsten Anwendungsfälle,
- priorisieren diese mit bewährten Methoden und
- erstellen einen Use Case Backlog für die Umsetzung.
Dabei kombinieren wir unsere Expertise aus Data Strategy und Nachhaltigkeitsberatung – und bringen ein erprobtes Portfolio an Sustainability Use Cases mit.
Interesse an einem Austausch zu dem Thema? Dann melde dich bei uns.