

Daten sind das neue Öl, das neue Gold… Überschriften wie diese liest man momentan wie Sand am Meer. Ja, Daten sind wichtig. Darüber sind wir uns inzwischen alle im Klaren. Und Daten werden produziert. Jeden Tag, jede Minute, in Massen. Von Privatpersonen und auch von Unternehmen. Und jedes Unternehmen hat die verschiedensten datenerzeugenden Systeme: CRM, ERP, BDE und noch viele weitere dreistellige Akronyme.
Oft ist eine historische Speicherung der Daten in diesen Systemen nicht vorgesehen, wodurch diese bei dem Überschreiben der Datensätze verloren gehen. Ein weiteres Problem ist die Vielfalt der Systeme. Für meine Business-Intelligence-Auswertung benötige ich Daten aus verschiedenen Systemen. Diese Systeme sind in den meisten Fällen nicht nur voneinander abgegrenzt, sondern haben auch unterschiedliche Datenspeicherungssysteme. Verschiedene Datenbanktypen, -strukturen und Flat Files erfordern einen ETL-Prozess, um die Daten sinnvoll zu einem Gesamtüberblick zusammenzuführen. Denn genau dabei geht es ja bei Business Intelligence (BI): Einen Gesamtüberblick über alle relevanten Daten aus verschiedenen Systemen des Unternehmens zu bekommen.
BI-Auswertungen sind oft sehr agil. Es gibt immer wieder neue Anforderungen oder neue Fragestellungen, die beantwortet werden müssen. Im schlimmsten Fall muss dazu der ETL-Prozess angepasst oder ein neuer erstellt werden. Wie wäre es, wenn diese Anpassungen nicht mehr nötig wären? Wenn alle Daten aller Systeme schon in einem großen Topf gesammelt wären und nur noch darauf warten, für BI-Auswertungen oder Data-Science-Projekte genutzt zu werden. An dieser Stelle kommt ein Data Warehouse ins Spiel. Auch hier sind ETL-Prozesse weiterhin nötig, um die Daten der Quellsysteme zum Data Warehouse zu transportieren. Wenn diese Prozesse allerdings feststehen, müssen sie nur noch selten angepasst werden. Die Daten bleiben gesammelt im Data Warehouse und können von dort aus weiter modelliert werden.
Doch wie bzw. wo baue ich mir ein Data Warehouse am besten auf? Nutze ich meine lokale Serverinfrastruktur oder ziehe ich die Daten besser in die Cloud? Hierbei gibt es verschiedene Aspekte zu berücksichtigen.
Sicherheit
Gerade in Deutschland ist die Skepsis gegenüber der Cloud immer noch sehr hoch. Der Gedanke, dass die eigenen Daten irgendwo im Internet und nicht mehr unter der eigenen Kontrolle sind, lässt viele Leute immer noch schlecht schlafen. Im Privatgebrauch ist es dagegen oft schon selbstverständlich, seine Fotos in der Apple Cloud zu speichern, Kontaktinformationen mit Google zu synchronisieren oder den Mietvertrag bei Dropbox einzuscannen.
Liegen die Daten in meinem Unternehmen, in meiner IT-Infrastruktur, kann ich selbst für die Sicherheit sorgen. Doch wie viele Personen kümmern sich im Unternehmen um die Sicherheit dieser Infrastruktur? Je nach Unternehmensgröße vielleicht fünf oder sogar zehn? Natürlich nicht Vollzeit, sondern eher nebenbei. Bei den großen Cloud-Anbietern sind es tausende Mitarbeiter, die Tag für Tag mit der Sicherheit der Infrastruktur beschäftigt sind. Sicherheit ist dort die höchste Priorität.
Integration
Eine Frage, die nicht außer Acht gelassen werden sollte, ist: Wie kommen meine Daten in das Data Warehouse? In einer On-Premise Umgebung gibt es mit Talend, Attunity, Apache NiFi, KNIME und vielen anderen Tools, mehrere Möglichkeiten, um ETL-Strecken zu erstellen und zu verwalten.
Bei der Cloud-Umgebung stellt sich zunächst immer die Frage, wie die Daten von meinem Unternehmensnetzwerk in die Cloud gelangen. Die klassische Lösung ist, die entsprechende Cloud per Site-to-Site-VPN-Verbindung an das eigene Netzwerk anzuschließen. Dann gibt es keinen Unterschied mehr zwischen der Kommunikation innerhalb des Unternehmensnetzwerks oder zur Cloud. Doch auch die genannten Data-Integration-Tools bieten (teils kostenpflichtige) Möglichkeiten, Daten in die Cloud zu transportieren. Außerdem bieten auch die großen Cloud-Anbieter eigene Data-Integration-Tools an, um ihre Umgebung zugänglich zu machen. Management-Umgebungen wie beispielsweise Snowflake können den Prozess zusätzlich erleichtern.
Datenwachstum
Die gesammelten Daten wachsen kontinuierlich in Unternehmen. Ob dies linear oder eher exponentiell geschieht, ist manchmal schwierig vorauszusehen. Es muss also dafür gesorgt werden, dass definitiv genug Speicherplatz vorhanden ist, um auch in Zukunft alle Daten speichern zu können. Bei einer On-Premise-Lösung muss daher auf lange Sicht gegebenenfalls neue Speicherkapazität in Form von Festplatten bzw. SSDs beschafft werden. Für eine Cloud-Lösung gilt dies genauso. Hier ist es allerdings eher nur ein Schieberegler in der Management-Oberfläche, der weiter aufgedreht werden kann, aber auch weitere Kosten verursacht.
Kosten
Ein sehr wichtiger und schwer durchschaubarer Punkt sind die Kosten. Natürlich kann ich irgendeinen Server nehmen, der bereits vorhanden ist und nicht genutzt wird. Darauf packe ich eine Datenbank und erstelle ein Data Warehouse. Die einzigen Kosten, die noch bleiben, sind die laufenden Kosten für den Stromverbrauch, Wartungsverträge und Backups. Letzteres ist umso wichtiger. Denn wenn der Server – aus welchem Grund auch immer – den Geist aufgibt und die Daten nicht mehr zu retten sind, war die ganze Mühe umsonst. Vergangenheitsdaten sind unwiderruflich verloren. Ein regelmäßiges Backup ist also hier wichtiger als je zuvor.
Erstelle ich ein Data Warehouse in der Cloud, brauche ich mich um den Server an sich nicht mehr zu kümmern. Die Datenbank läuft selbst in der Cloud und nicht mehr auf einem bestimmten Server.
Ein kleines Rechenbeispiel
Nehmen wir einen Server, der den Anforderungen eines Data Warehouses, vor allem hinsichtlich Random Access Memory (RAM) und Speicherplatz gerecht wird, können wir von ca. 5.000 Euro Beschaffungskosten ausgehen. Dazu kommen Wartungsverträge von ca. 200 Euro pro Jahr und die Kosten für eine Windows Server Lizenz sowie ggf. für eine MSSQL Server Lizenz. Die Lizenzkosten können natürlich gespart werden, wenn man auf nicht weniger gute OpenSource-Lösungen wie z.B. einer PostgreSQL-Datenbank auf Linux setzt. Zusätzlich müssen Stromkosten einkalkuliert werden. Unser Beispielserver verbraucht im 24/7-Betrieb in einem Jahr circa 4.000 Kilowatt Strom. Multipliziert mit den Kosten pro kWh von beispielsweise 10 Cent ergibt das 400 Euro Energiekosten.
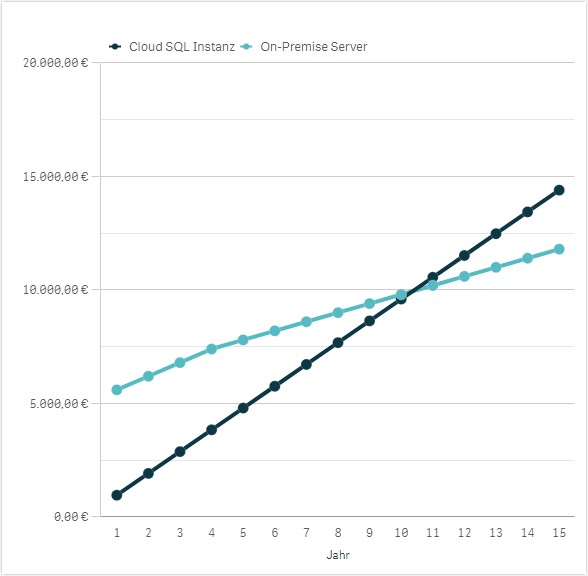
Die Kosten für eine SQL-Instanz mit ähnlichen Eckdaten liegen bei Azure oder AWS in etwa bei 50 bis 80€ im Monat. Dabei bietet sich die Platform-as-a-Service (PaaS) Variante an. Im Gegensatz zu Infrastructure-as-a-Service (IaaS) wird hier kein Server benötigt. Somit fallen auch keine Lizenzkosten und kein Administrationsaufwand für das Betriebssystem an. Die SQL-Instanz läuft in der Cloud ohne direkten Server in der Cloud.Vergleicht man also beide Modelle miteinander, kommt man im ersten Jahr auf 5.600 Euro für die On-Premise-Lösung und auf 600 bis 960 Euro für die Cloud-Lösung im ersten Jahr.
Der Vorteil der On-Premise-Lösung ist, dass ich den Server nur einmal beschaffen muss. Die Abschreibungsdauer liegt zwar i.d.R. bei vier Jahren, aber die meisten Server werden dann doch gute 10 Jahre gehalten. Doch erst nach 14 Jahren würde sich bei diesem Beispiel die On-Premise-Variante als günstiger erweisen als die Cloud-Variante. Selbst wenn der Wartungsvertrag nach dem fünften Jahr nicht mehr weitergezahlt wird, liegt der Schnittpunkt erst im Jahr 10. Spätestens dann ist ohnehin ein neuer Server fällig. Außerdem sind hier die Kosten für Backups noch gar nicht miteingerechnet. Diese Backups sind bei den Cloud-Datenbanken nicht nötig, da es dort integrierte Mechanismen gibt.
Fazit
Um die stetig wachsenden Datenmengen optimal speichern und sinnvoll nutzen zu können, benötigen Unternehmen ein effizientes Data Warehouse. On-Premise- und Cloud-Lösungen bieten verschiedene Vorteile für Unternehmen. Ein kleines Rechenbeispiel zeigt jedoch relativ offensichtlich, dass es sich nicht lohnt, einen eigenen Server für ein Data-Warehouse zu beschaffen. Sowohl Kosten als auch Aufwand übersteigen um ein Vielfaches die einer Cloud-Lösung. Wird kein Server beschafft, sondern eine virtuelle Maschine in einer bestehenden VMWare- oder HyperV-Umgebung erstellt, bleiben nur noch die Kosten für Lizenzen, Speicherplatz und Backups.
Gerade die letzten beiden Punkte sind die großen Stärken der Cloud. Die einfache Skalierbarkeit und integrierte Backup-Mechanismen sind ebenfalls kaum zu schlagen. Eine alternative Lösung wäre eine Hybrid-Umgebung, bei der man auf einer eigenen lokalen virtuellen Maschine startet und bei Bedarf Cloud-Power hinzuzieht. Bis auf einen geringen Kostenvorteil gibt es aber auch hier keinen Mehrwert.