

Data is the new oil, the new gold… Headlines like these are a dime a dozen these days. Yes, data is important. We are all aware of that by now. Data is produced. Every day, every minute, in masses. By private individuals and also by companies. Every company has the most diverse data generating systems: CRM, ERP, BDE and many more three-digit acronyms.
Often there is no historical storage of data in these systems, which means that the data is lost when the records are overwritten. Another problem is the diversity of these systems. For my business intelligence analytics, I need data from different systems. In most cases, these systems are not only separated from each other, but also have different data storage systems. Different database types, structures and flat files require an ETL (Extract, Transform, Load) process to bring the data together in a meaningful way to create a complete overview. This is exactly what business intelligence (BI) is all about: getting a complete overview of all relevant data from different systems in the company.
BI evaluations are often very agile. There are always new requirements or questions that need to be answered. In the worst case, the ETL process may have to be adapted or a new one created. What happens if these adjustments are no longer necessary? If all data from all systems are already collected in a large pot and just waiting to be used for BI evaluations or data science projects. This is where a data warehouse comes into play. Here, too, ETL processes are still necessary to transport the data from the source systems to the data warehouse. However, once these processes are established, they rarely need to be adapted. The data remains collected in the data warehouse and can be further modeled from there.
But how and where is the best way to build a data warehouse? Do I use my local server infrastructure, or do I better move the data into the cloud? There are various aspects to be considered here.
Security
Skepticism about the cloud is still very high. The idea that your own data is somewhere on the internet and no longer under your own control still causes many people to worry. In private use, on the other hand, it is often a matter of course to store your own photos in the Apple Cloud, synchronize contact information with Google or scan the rental contract in Dropbox.
If the data is stored in my company, in my IT infrastructure, I can take care of the security myself but how many people in the company take care of the security of this infrastructure? Depending on the size of the company, maybe five or even ten? Not full-time, of course, but rather on the side. The large cloud providers have thousands of employees who work on infrastructure security every day. Security is the top priority there.
Integration
A question that should not be ignored is: How does my data get into the data warehouse? In an on-premise environment, there are several ways to create and manage ETL routes using Talend, Attunity, Apache NiFi, KNIME and many other tools.
In the cloud environment, the first question that always comes up is how the data from my corporate network gets into the cloud. The classic solution is to connect the corresponding cloud to your own network via site-to-site VPN connection. Then there is no difference between communication within the corporate network or to the cloud. However, the data integration tools mentioned above also offer (in some cases for a fee) way of transporting data to the cloud. In addition, the large cloud providers also offer their own data integration tools to make their environment accessible. Management environments such as Snowflake can further facilitate the process.
Data growth
The collected data grows continuously in companies. Whether this happens linearly or rather exponentially is sometimes difficult to predict. Therefore, it must be ensured that there is enough storage space to store all data in the future. In the long term, an on-premise solution may therefore require new storage capacity in the form of hard disks or SSDs. The same applies to a cloud solution. Here, however, it is rather just a slider in the management interface that can be turned up further, but also causes additional costs.
Costs
A very important and difficult to understand point is the cost. Of course, I can use any server that already exists and is not used. I then put a database on it and create a data warehouse. The only costs that remain are the running costs for power consumption, maintenance contracts and backups. The latter is even more important. This is because if the server – for whatever reason – goes down the drain and the data can no longer be saved; all the effort was in vain. Historical data is irrevocably lost. A regular backup is therefore more important than ever before.
If I create a data warehouse in the cloud, I no longer need to worry about the server itself. The database itself runs in the cloud and no longer on a specific server.
A small calculation example
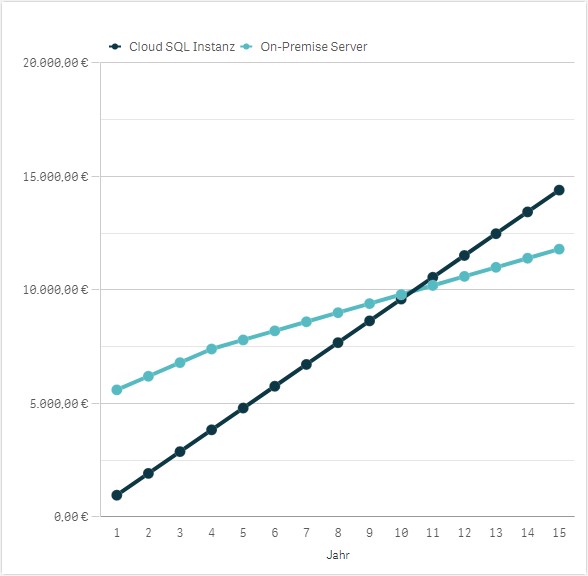
If we take a server that meets the requirements of a data warehouse, especially with regard to random access memory (RAM) and storage space, we can assume procurement costs of about 5,000 euros. In addition, there are maintenance contracts of approx. 200 Euro per year and the costs for a Windows Server license and, if necessary, a MSSQL Server license. The license costs can of course be saved if you use a poorer quality OpenSource solution such as a PostgreSQL database on Linux. In addition, electricity costs must be considered. Our example server consumes about 4,000 kilowatts of electricity in 24/7 operation in one year. Multiplied by the costs per kWh of, for example, 10 cents, this results in energy costs of 400 euros.
The costs for an SQL instance with similar key data are about 50 to 80 € per month for Azure or AWS. The Platform-as-a-Service (PaaS) variant is a good choice. In contrast to Infrastructure-as-a-Service (IaaS), no server is required here. Therefore, there are no license costs and no administration costs for the operating system. The SQL instance runs in the cloud without a direct server, so if you compare the two models with each other, the on-premises solution costs 5,600 € in the first year and the cloud solution between 600 and 960 € in the first year.
The advantage of the on-premises solution is that I only have to purchase the server once. The amortization period is usually four years, but most servers are then held for a good 10 years. However, it would take 14 years before the on-premises variant would prove cheaper than the cloud variant in this example. Even if the maintenance contract is no longer paid after the fifth year, the point of intersection is only in year 10. A new server is due anyway, at the latest by then. Moreover, the costs for backups are not even included here. These backups are not necessary with cloud databases, as there are integrated mechanisms.
Conclusion
To be able to optimally store and sensibly use the constantly growing data volumes, companies need an efficient data warehouse. On-premises and cloud solutions offer various advantages for companies. However, a small calculation example shows relatively obviously that it is not worthwhile to procure a separate server for a data warehouse. Both costs and effort exceed those of a cloud solution many times over. If no server is procured, but a virtual machine is created in an existing VMWare or HyperV environment, all that remains are the costs for licenses, storage space and backups.
The last two points are the great strengths of the cloud. The simple scalability and integrated backup mechanisms are also hard to beat. An alternative solution would be a hybrid environment, where you start on your own local virtual machine and draw on cloud power when needed. However, apart from a small cost advantage, there is no added value here either.
How did you set up your data warehouse? Do you have any further questions on this topic, or would you like to discuss it? Then please feel free to contact me!