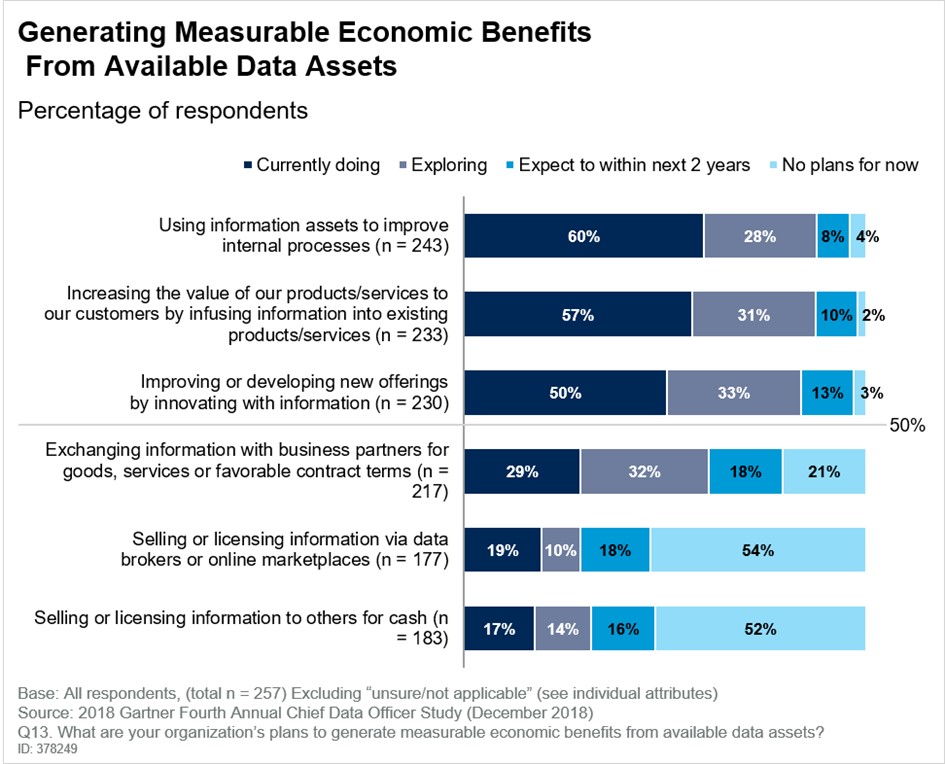
Datenarchitektur als strategischer Hebel
Nie zuvor war Dateninfrastruktur so zentral für den Unternehmenserfolg wie heute. Ob im Marketing, im Controlling oder in der Produktentwicklung – datengetriebene Entscheidungen sind längst Alltag. Doch während sich viele Unternehmen mit der richtigen Analyse beschäftigen, wird die zugrunde liegende Architektur oft vernachlässigt.
Dabei entscheidet gerade sie über Skalierbarkeit, Flexibilität und Zukunftsfähigkeit.
Im Zentrum dieser Architektur steht eine Grundsatzentscheidung: ETL oder ELT? – zwei Methoden, um Daten aus Quellsystemen aufzubereiten. Dieser Blog beleuchtet, was hinter diesen Ansätzen steckt, wie sie sich entwickelt haben und warum ELT in der Cloud-Ära oft die bessere Wahl ist – aber nicht immer.
Rückblick: Von der Datenbewirtschaftung zum Lakehouse
Die Ursprünge von ETL reichen zurück bis in die 1970er Jahre. Damals formulierte Bill Inmon das Konzept des Data Warehousing: strukturierte Datenaufbereitung auf einer dedizierten Plattform, meist On-Premises.
Mit der Zeit entstanden darauf aufbauend Standards wie:
- ETL-Prozesse zur Datenintegration
- Relationale Datenbanken
- Modellierungsmethoden wie Star Schema, Snowflake Schema und später Data Vault
Die 2000er Jahre brachten erste spezialisierte BI-Tools (z. B. QlikView), und mit ihnen neue Anforderungen an Performance und Visualisierung. Doch der große Bruch kam 2011: Cloud Data Warehouses wie Google BigQuery und später Snowflake revolutionierten die Art, wie Daten gespeichert, verarbeitet und analysiert wurden.
Mit ihnen entstand ein neues Paradigma: ELT.
Was ist ETL – und warum war es lange Standard?
ETL steht für Extract, Transform, Load – also Extrahieren, Transformieren und Laden. Dieses klassische Verfahren zur Datenintegration war über viele Jahre hinweg der De-facto-Standard, insbesondere in traditionellen IT-Landschaften.
Der Prozess beginnt mit dem Extract-Schritt: Daten werden aus verschiedenen Quellsystemen wie Datenbanken, CRM- oder ERP-Systemen gelesen. Im zweiten Schritt, der Transformation, werden die Daten bereinigt, formatiert und harmonisiert – etwa durch das Entfernen von Duplikaten oder das Vereinheitlichen von Formaten. Schließlich folgt das Load, also das Laden der aufbereiteten Daten in ein Zielsystem, typischerweise ein Data Warehouse.
Vorteile:
- Hohe Kontrolle über Datenqualität und Transformation
- Guter Fit für On-Prem-Infrastrukturen mit limitierter Zielsystem-Leistung
- Bewährt in stark regulierten Branchen (Banken, Versicherungen, Gesundheitswesen)
Nachteile:
- Skalierung nur durch dedizierte ETL-Server möglich
- Lange Entwicklungszyklen, hoher Wartungsaufwand
- Wenig flexibel für neue Anforderungen oder Datenquellen
Typische Tools: Talend, Informatica, IBM DataStage, Microsoft SSIS
Was ist ELT – und warum ist es heute Standard?
Im Gegensatz zum klassischen ETL-Ansatz kehrt ELT das Prinzip um. Die drei Buchstaben stehen für Extract, Load, Transform – also Extrahieren, Laden und Transformieren. Der entscheidende Unterschied liegt in der Reihenfolge und im Ort der Transformation: Während bei ETL die Daten zunächst außerhalb des Zielsystems aufbereitet werden, geschieht das bei ELT direkt im Cloud Data Warehouse.
Zunächst werden die Daten wie gewohnt aus verschiedenen Quellsystemen extrahiert. Doch statt sie zunächst in einem Zwischensystem zu transformieren, erfolgt direkt der Load: Die Rohdaten werden unverändert in das Zielsystem geladen – etwa in moderne Cloud-Plattformen wie Snowflake, BigQuery oder Databricks. Die anschließende Transformation passiert dann innerhalb dieser Systeme – mit der vollen Rechenleistung der Cloud im Rücken.
Vorteile:
- Skalierbarkeit: Cloud-Plattformen wie Snowflake, BigQuery oder Databricks skalieren Rechenleistung dynamisch
- Flexibilität: Rohdaten bleiben erhalten – ideal für explorative Analysen und KI-Anwendungen
- Schnelligkeit: Kurze Time-to-Value durch moderne Tools und Self-Service
Nachteile:
- Höhere Anforderungen an Zielsysteme (Kosten, Governance)
- Kontrollverlust bei mangelndem Datenmanagement
- Erfordert moderne Datenstrategie und Plattform-Kompetenz
Typische Tools: Fivetran, Airbyte, dbt, Qlik Talend Cloud, Azure Data Factory (im ELT-Modus)
Hybride Strategien: Wenn ETL und ELT koexistieren
In der Praxis ist es selten ein “Entweder-Oder”. Vielmehr ergänzen sich beide Ansätze – etwa in folgenden Szenarien:
| Use Case | ETL | ELT |
| Klassische DWH-Prozesse (On-Prem) | ✅ | ❌ |
| Cloud-native Data Plattform | ❌ | ✅ |
| Komplexe Transformation vor dem Laden | ✅ | 🔄 (teilweise) |
| Explorative Analytik, Data Science, AI | ❌ | ✅ |
| Applikationsintegration (z. B. ERP-CRM) | ✅ | ❌ |
| Reverse ETL (Daten zurück in Systeme | ✅ | 🔄 (teilweise |
Beispiel: Moderne Architektur mit ELT
Ein Unternehmen möchte Marketing- und Vertriebsdaten aus Salesforce, HubSpot und Webtracking in einem Snowflake-Data Warehouse analysieren.
- Replikation der Rohdaten mit Fivetran oder Qlik Talend Cloud (Extract & Load)
- Modellierung & Transformation mit dbt (Transform)
- Visualisierung mit Looker oder Power BI
- Zusätzliche Use Cases: Forecasting mit Python, Reverse ETL in HubSpot mit Census
→ Schnell, skalierbar, flexibel. Und: Jede Ebene ist modular ersetzbar (Composable Architecture).
Zukunftstrends: Was bewegt die Branche?
Die Welt der Datenverarbeitung entwickelt sich rasant weiter, und moderne ELT-Architekturen stehen im Zentrum vieler aktueller Innovationen. Ein klarer Trend ist der Einsatz von KI-basierten Helfern, etwa in Form von AI Pair Development oder sogenannten Copilots. Diese Tools unterstützen Daten-Teams beim Schreiben von SQL-Abfragen, beim Definieren von Datenmodellen oder auch bei der automatisierten Dokumentation – und steigern damit nicht nur die Produktivität, sondern auch die Qualität.
Gleichzeitig gewinnt Streaming und Near-Realtime ELT an Bedeutung. Gerade bei Anwendungsfällen mit IoT-Geräten oder umfangreichen Logdaten sind zeitnahe Analysen entscheidend. Hier kommen häufig spezialisierte Tools wie Apache Kafka oder Apache Flink zum Einsatz, die Daten nahezu in Echtzeit verarbeiten können.
Auch die technologische Basis verschiebt sich: Moderne Open Table Formats wie Apache Iceberg, Delta Lake oder Apache Hudi ermöglichen es, ELT-Prozesse direkt auf Data Lakes auszuführen – etwa mit Plattformen wie Databricks oder Microsoft Fabric. Dadurch entstehen hybride Architekturen, die Flexibilität und Performance kombinieren.
Ein weiterer wichtiger Trend ist der Aufstieg von Data Mesh und Data Products. Hierbei werden Daten nicht mehr zentral verwaltet, sondern in Verantwortung der jeweiligen Fachdomänen dezentral bereitgestellt. ELT spielt in diesem Kontext eine Schlüsselrolle als Enabler für Domain Ownership und flexible Datenarchitekturen.
Nicht zuletzt rücken auch FinOps-Prinzipien und Nachhaltigkeitsaspekte in den Fokus: Durch gezielte Reduzierung von Datenbewegung und optimierte Ressourcennutzung lassen sich nicht nur Kosten sparen, sondern auch der Energieverbrauch senken – ein wachsendes Anliegen in Zeiten von ESG und Green IT.
Fazit und Empfehlung
ELT ist zweifellos der Weg der Zukunft – doch das bedeutet nicht, dass ETL ausgedient hat. Wer heute neu startet oder bereits konsequent in der Cloud arbeitet, sollte auf jeden Fall auf ELT setzen. Die Vorteile moderner Cloud-Plattformen in Kombination mit leistungsfähigen ELT-Tools machen diesen Ansatz zum klaren Favoriten für datengetriebene Organisationen.
Gleichzeitig gilt: Unternehmen mit bestehenden ETL-Strukturen oder besonders komplexen Anforderungen müssen nicht alles umstellen. In vielen Fällen bieten hybride Architekturen, die ETL und ELT kombinieren, eine pragmatische und zukunftssichere Lösung.
Entscheidend ist dabei nicht das konkrete Tool, sondern die zugrunde liegende Datenstrategie. Nur wer diese klar definiert, kann langfristig erfolgreich mit Daten arbeiten – unabhängig von Technologie oder Architekturmodell.
Ein zentraler Leitsatz sollte dabei sein: Build for Flexibility. Datenarchitekturen müssen heute so gestaltet sein, dass sie sich schnell und effizient an neue Anforderungen anpassen lassen – sei es für generative KI, neue Anwendungsfälle oder technologische Entwicklungen, die heute vielleicht noch gar nicht absehbar sind.

Du willst mehr darüber erfahren, wie eine moderne Datenplattform in deinem Unternehmen aussehen kann? Schreib mir auf LinkedIn oder buch dir direkt einen Termin über meinen Kalender.